Data is king and it outlives applications. Applications outlive integrations. Organizations striving to become data-driven need to institute efficient, intelligent, and robust ways for data processing. Data engineering addresses many of the aspects of this process.
Success of organizations is predicated on their ability to convert raw data from various sources into useful operational and business information. Data processing and extracting business intelligence requires a wide range of traditional and new approaches, systems, methods, and tooling support beyond those offered by the existing OLAP and Data Mining systems.
Data engineering is a software engineering practice with a focus on design, development, and productionizing of data processing systems. Data processing includes all the practical aspects of data handling, including:Data acquisition, transfer, transformation, and storage on-prem or in the cloud. In many cases, data can be categorized as Big Data.
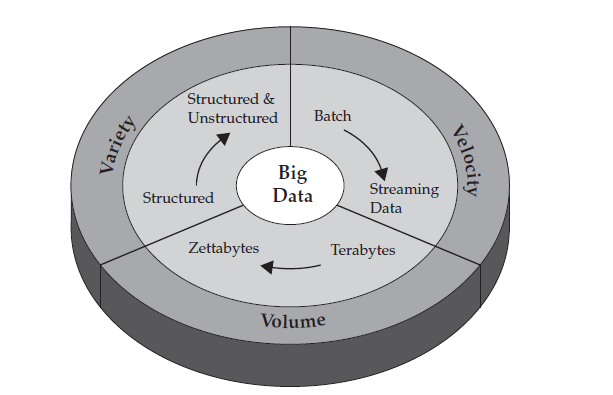
Gartner’s Definition of Big Data
Gartner’s analyst Doug Laney defined three dimensions to data growth challenges: increasing volume (amount of data), velocity (speed of data in and out), and variety (range of data types and sources).
In 2012, Gartner updated its definition as follows: “Big data are high volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision making, insight discovery and process optimization.”
Volume
Data sizes accumulated in many organizations come to hundreds of terabytes, approaching the petabyte levels.
Variety
Big Data comes in different formats as well as unformatted (unstructured) and various types like text, audio, voice, VoIP, images, video, e-mails, web traffic log files entries, sensor byte streams, etc.
Velocity
High traffic on-line banking web site can generate hundreds of TPS (transactions per second) each of which may be required to be subjected to fraud detection analysis in real or near-real time.
 More Definitions of Big Data
More Definitions of Big Data
There are other definitions and understandings of what Big Data is.
Everybody seems to agree that the data gets mystically morphed into the Big Data category when traditional systems and tools (e.g. relational databases, OLAP and data-mining systems) may either become prohibitively expensive or found outright unsuitable for the job.
 Source: http://en.wikipedia.org/wiki/File:DataScienceDisciplines.png
Source: http://en.wikipedia.org/wiki/File:DataScienceDisciplines.png
Data engineers are software engineers who have the primary focus on dealing with data engineering tasks. They work closely with System Administrators, Data Analysis, and Data Scientists to prepare the data and make it consumable in subsequent advanced data processing scenarios. Most of these activities fall under the category of ETL (Extract, Transform and Load) processes. Practitioners in this field deal with such aspects of data processing as processing efficiency, scalable computation, system interoperability, and security. Data engineers have knowledge of the appropriate data storage systems (RDBMS or NoSQL types) used by organizations they work for and their external interfaces. Typically, data engineers have to understand the database and data schemas as well as the APIs to access the stored data. Depending on the task at hand, internal standards, etc., they may be required to use a variety of programming languages, including Java, Scala, Python, C#, C, etc.
Solid programming skills in one or more programming languages-Python appears to be a “must-to-know” language. Data interoperability considerations, various file formats, etc. Infrastructure-related aspects specific to your organization-Ability to work with DBAs, SysAdmins, Data Stewards, and in DevOps environments, Understanding data upstream (sources, data ingestion pipelines) and downstream. Efficient ETL- How to optimize processing subject to constraints, including time, storage, errors, etc. Data Modeling- Data (de-)normalization on SQL and NoSQL systems, matching a use case with a choice of technology. Good analytical skills- Comprehending Data Physics aspects of data processing (data locality, CAP theorem), Ability to come up with options for quantifiable data measurements and metrics (what is quality data?).
Now, with this data product in place, a whole range of usage / business analytics can be performed using it. All the elements of designing and building the CDDB database leading to the point where business analysts / data scientists took over had been dealt with by data engineers.
Data wrangling (a.k.a. munging) is the process of organized data transformation from one data format (or structure) into another. Normally, it is part of a data processing workflow the output of which is consumed downstream, normally, by systems with focus on data analytics / machine learning. Usually, it is part of automated ETL (Extract, Transform, and Load) activities. Specific activities include: Data cleansing, removing data outliers, repairing data (by plugging in some surrogate data in place of the missing values), data enhancement / augmenting, aggregation, sorting, filtering, and normalizing.
Data processing systems are written in different programming languages and to ensure efficient data exchange between them, the following interoperable data interchange formats are used:
 More Definitions of Big Data
More Definitions of Big Data 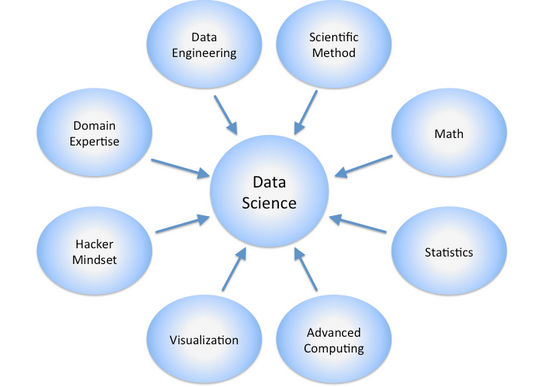 Source: http://en.wikipedia.org/wiki/File:DataScienceDisciplines.png
Source: http://en.wikipedia.org/wiki/File:DataScienceDisciplines.png{kind=link}